Voice Component Modeling
Improving Modeling of Vintage Poly Synths and Acoustic Analog Instruments Through Voice Variance

Preface:
This site explores approaches to
modeling the imperfections of classic synthesizers and real world analog ensemble instruments. It provides analysis and methods to get you closer to vintage analog poly synth character and more realistic acoustic instrument sounds.
It's focused on improving polyphonic voice modeling and exhibits biggest gains in synth pads, strings, brass and other analog or acoustic voices with longer attack, decay or release times.
These approaches can be useful for analog and digital synths.
Even the latest flagship VCO poly synths can benefit from this type of approach, if the goal is to emulate older classic poly synths or real world analog instruments.
 Note: Since initially publishing this info back in 2018, several synth designers have begun to implement these approaches, most notably the Vintage Knob from Sequential and some software VST synths.
Note: Since initially publishing this info back in 2018, several synth designers have begun to implement these approaches, most notably the Vintage Knob from Sequential and some software VST synths.
In addition, the latest Arturia Polybrute 2.0 firmware now has some expanded vintage voice modeling controls. (I was asked to help on the Beta team for PolyBrute and consulted with them to help curate the new vintage modeling parameters).
In 2022, I worked on the Beta Team for Groove Synthesis 3rd Wave - which now features a very good voice modeling implementation (via misc menu circuit drift parameter).
For a list of synths using vintage voice modeling, click here.
I've performed extensive sound design testing using my Prophet Rev2, Arturia PolyBrute, and Behringer Deepmind synths - the techniques described in this article work well with both (with some limitations) - the same type of modeling is possible with other poly synths that offer a fully featured gated sequencer and mod matrix, or voice number mod source.
For patches where Osc Slop, Osc Drift or Parameter Drift was used previously, this approach can replace that functionality... This is a more defined, accurate and repeatable method to obtain vintage per-voice variance.
Specifics are discussed below, along with recommendations for a next generation implementation of this type of voice-based component modeling.
| "This is "wizard stuff" that shows what this synth is capable of" - BM |
"Wow, makes total sense and never realized this was even a possibility" - JS |
| "Absolutely brilliant" - J3PO |
"Just purchased this. I got lost in the pad sounds for hours!" - TE |
| "VCM is a crazy amazing trick that fixes the sonic issues I sometimes have with this and other modern analogue synths" - NY |
"Completely blown away by @creativespiral's patches. Beautiful lush sounding, very organic and massive." - GH |
| "This is an amazing approach! At first I thought maybe you were trying to reinvent the wheel in regards to some sort of slop functionality, but this is a way more granular approach." - JG |
"I've bought many sound banks and while most of them are good, this one is in a totally different league. The best thing is that all patches are extremely playable. My Rev 2 suddenly feels more organic and alive then ever." - MS |
| "Wow this is an amazing resource!" - OW |
"Great set of patches! Congrats!" - OM |
| More VCM Comments and Reviews |
The Sequential Rev2 Forum Discussion |
Video Demonstrations:
Below are some YouTube videos demonstrating what Vintage Voice Modeling sounds like in a more raw form, and in the context of a more developed sound design scenario. Check out the VCM vs Raw DCO Sound for an A/B test between the two.
Free Vintage VCM Patch Template for Hydrasynth
Groove Synthesis 3rd Wave Vintage Variances
Free Vintage Patches for Prophet Rev 2
Free Vintage Patches for PolyBrute
Behringer Deepmind Vintage Soundset
VCM Volume 1 Soundset for Prophet Rev2
PolyBrute Vintage Soundset
VCM ++ Volume 2 Soundset for Prophet Rev 2
Voice Modeling on Moog One with Tim Shoebridge
Analysis of Sequential's Vintage Knob
J3PO Rev2 Soundset Using Voice Modeling
Advanced Sound Design Tutorial with VCM

Overview:
Much of the character in classic poly synths and real world analog instruments arises from variance and imperfections that occur on a voice-to-voice basis. If you analyze an old VCO poly synth, you will find that once it has warmed up, each voice has unique fine tuning offsets as well as other differences associated with the specific electrical characteristics in the VCO, VCF, VCA and ENV circuits.

In addition, if you analyze the voice components of a cello or violin or guitar (the strings / oscillators), each one will have a specific fine tuning offset. These tuning offsets and other characteristics tend to be fairly stable. The contrast between other voices produces unique character when multiple notes are played simultaneously. There may be some detuning drift motion, but voices (and their components) will tend to hold their given detuned offsets fairly well, at least during the time-frame of a given musical phrase.
The current paradigm for modeling multi-voice instruments with modern synthesizers is too reliant on applying randomness to give voice tuning offsets, and introducing exaggerated detuning motion per voice, rather than modeling each voice independently with unique offsets and component characteristics.
By modeling voices down to their component level with a lookup table or voice number modulation, we can give better definition to the character of individual voices.
In addition to oscillator tuning offsets, there are dozens of additional characteristics than can be modeled on a per voice basis, depending on which instruments are being synthesized. This approach can increase authenticity and realism when modeling classic synths from the past, as well as other real world analogs like wind instruments, stringed instruments and choirs.
For future generations of synths, this type of per voice, per component variance could be included as a standard option. (Note: Since originally publishing this article on Voice Modeling, Sequential has released their new "Vintage Knob" algorithm in several synths (P5r4, P6, OB6), that does this type of curated, per voice variance to various parameters) In the meantime, we can achieve some of this behavior by doing some creative modulation routing with modern poly synths. In this paper, we will explore using the Dave Smith Sequential Prophet Rev2 synthesizer to achieve such results.
Part 1: Voices and Component Level Variance
 Beautiful Imperfections
Beautiful Imperfections
Perfect tuning, or parity of tuning between voices can be beneficial for certain types of sound design, but often, the most beautiful, rich sounds arise when there are small musical imperfections and variance from voice to voice.
Below, we will be primarily focused on imperfections in oscillator tuning, however this same approach can apply to dozens of other characteristics that can be modeled on a per-voice basis.
In the following sections we will explore a balance between
modeling order and
applying randomness, down to the voice and component circuit level.
The Current Paradigm
All modern synths include tools to mimic tuning imperfections, such as Oscillator Fine Tuning, LFO modulation, or some form of Oscillator Slop / Voice Detuning.
These approaches do generate character
similar to old VCO poly synths and analog multi-voice instruments, but there are downsides to each approach (described below)
The general paradigm has been focused on "approximation by randomness and drifting movement", with not enough focus on underlying order and stability.
While randomness and drift is still present, and a good tool to use, we can improve modeling techniques and analog character by taking a closer look at voice-by-voice and component-by-component modeling.
 The Fundamental Components of Sound Generation
The Fundamental Components of Sound Generation
For acoustic instruments like a violin or guitar, the fundamental voice component is a tensioned string. For old analog poly synths, the fundamental voice components are the oscillators (VCOs) installed on each voice board.
Each of these oscillator circuits are discreet electrical components, with variance to their performance characteristics.
The rest of the signal chain, including VCFs and VCAs will shape and color the sound and may have independent characteristics and electrical variances from voice-to-voice.
| Six Voices |
Voice 1 |
Voice 2 |
Voice 3 |
Voice 4 |
Voice 5 |
Voice 6 |
|
| Tuning Offsets |
Cents |
Cents |
Cents |
Cents |
Cents |
Cents |
| Osc 1 Fine Tune |
0 |
+3 |
+6 |
-2 |
+1 |
+2 |
| Osc 2 Fine Tune |
-1 |
0 |
+10 |
0 |
+3 |
0 |
| Osc 3 Fine Tune |
-1 |
-2 |
+7 |
-3 |
-5 |
0 |
|
| Osc 1 Intonation |
-3 |
-1 |
-2 |
-1 |
-3 |
-4 |
| Osc 2 Intonation |
-2 |
-4 |
-2 |
-1 |
-3 |
-3 |
| Osc 2 Intonation |
-2 |
-2 |
-3 |
-4 |
-3 |
-5 |
| Osc 1 Freq Jitter |
0.3 |
0.2 |
0.6 |
0.3 |
0.4 |
0.3 |
|
| Offset Value |
Value |
Value |
Value |
Value |
Value |
Value |
| VCF Cutoff |
3 |
0 |
5 |
4 |
0 |
2 |
| VCF Attack |
+1 |
+3 |
+4 |
0 |
+2 |
+2 |
| VCF Decay |
+2 |
0 |
+1 |
+2 |
0 |
+1 |
| VCF Release |
+1 |
+1 |
0 |
+4 |
0 |
+3 |
|
| Offset Value |
Value |
Value |
Value |
Value |
Value |
Value |
| Osc 1 Settle Env |
3 |
2 |
5 |
0 |
1 |
7 |
| Osc 1 Glitch Env |
0 |
0 |
2 |
0 |
1 |
0 |
| Osc 1 Level |
2 |
-1 |
1 |
3 |
3 |
-2 |
| Osc 1 Shape |
1 |
0 |
2 |
2 |
4 |
2 |
| VCA Env Offset |
-1 |
-2 |
0 |
0 |
2 |
-3 |
| Voice Noise |
6 |
2 |
9 |
3 |
4 |
1 |
| Etc... Each VCO, VCF and VCA will have unique characteristics on a per voice basis. |
A Synth with "Lots of Character"
Let's take a MemoryMoog for example - this is a synth that is generally regarded as having "ample character" (aka: imperfections), and has often been thought of as a synth that will never be accurately modeled in modern synths.
The MemoryMoog has six polyphonic voices that can be played at a given time, each with three oscillators. That is a total of eighteen voltage controlled analog oscillators.
If you go through and measure the tuning of each of those eighteen oscillators, you will find some drifting motion and semi-random behavior, but overall, once the synth has warmed up, each of the voices, and the oscillators within those voices will tend to hold their general tuning offsets for a given note with only minor drift, at least over period of time associated with a given musical passage.
If you took each measurement and wrote it down into a table, it might look like this mockup table above. You may find that some voices are very close to being in tune on all three oscillators, while other voices (like Voice 3 in the example) may have more significant detuning. As you're playing chords, you will sometimes get the detuned voices, while other times voices may be nearly perfect. There will be patterns of detuning that repeat depending on chord progressions and how many notes you play at a given time.
Note: most synths default to a cyclical / round-robin type of voice assignment of new notes, but there are others (like Jupiter 8) that have voice modes which may reset and backtrack to lowest available voice. In both cases however, this Voice Component Modeling method proves to be superior to traditional detuning methods when playing chords. More on this topic later.
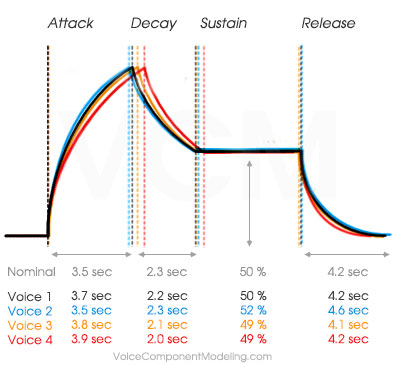 Per Voice Variance to Envelope Timing in Classic Synths
Per Voice Variance to Envelope Timing in Classic Synths
The envelope generators (EGs) and associated circuitry on classic poly synths were also analog designs. Small differences in electrical tolerances of the envelopes from voice to voice lead to small variances in envelope ADR timing, causing temporal offsets to the exact timing of Attack, Decay and Release stages. The image to the right is an example of how four analog voices might differ at a given setting.
The audible effects of these ADR Envelope timing offsets are most pronouced with high resonance values in the filter section, or with stacked, or unison sound designs, where multiple voices are triggered simultaneously and released simultaneously. In unison or stack patches where with high resonant filter amounts, the temporal offset of each voice's filter peak can produce a massive, organic filter sweep sound.
Read More about Envelope ADR Voice Modeling Here
Saving a Character Snapshot
The approach described in this article allows you to save a snapshot of a given synth character or acoustic poly voice sound, in a specific environment.
One issue that owners of old poly synths have to deal with is changes of the synth's performance from week to week, month to month, and venue to venue.
If you fire up your MemoryMoog on a given day, you may find that it's the most beautiful, perfect synth - full of interesting character. But a month later, it may not have the same magic, due to differences in tuning offsets.
Alternatively, try and bring a MemoryMoog on tour and you may find you're playing a different instrument at each venue. At a hot and humid summer concert, you may fire up your instrument and it may sound like crap, or conversely, the tuning imperfection might line up in a fashion that is majestic.
This method allows you to fine tune "snapshots" of given voice and component tuning offsets for a given environment and time. You can save patches or templates of the same model of old VCO synth in different states.
Part 2: Downsides of Existing Approaches
There are several different approaches that synth sound designers take to give imperfections and add character to patches. Below, we'll look at approaches for oscillator detuning, and discuss the downsides to each, in regards to modeling per-voice character.
Two Voices, Two Osc Each, Same Fine Detune Offset
Above: Each window above shows a voice with two oscillators. Natural Wave Interference Motion is created by a fine tune offset between two oscillators. The bottom window shows the same fine tune offset, but one octave up. There is too much detune parity between these two voices with the same exact osc tuning differences... ie: this would rarely occur with old VCO synths or real world analog instruments.
Osc Fine Tune
One basic method at our disposal is that we can purposely detune an oscillator.
For instance, we may have Osc 1 perfectly tuned, but set Osc 2 to a value of +7 cents.
This can produce a desireable imperfection between the oscillators within each voice, but since it is applied equally to all voices, this doesn't address the voice-to-voice differences that we're seeking to model from classic synthesizers and real world analog instruments.
There is too much parity between each voice (ie: they all will have the exact same detuning).
We're seeking to improve the realism of voice-by-voice differences.
We may still want some Osc Fine Tuning to reproduce some classic synth sounds, but beyond this global detuning method, each voice needs its own imperfections.
LFO Oscillator Routing
The second tool we have for generating tuning imperfections is LFO routings. By assigning an LFO to Osc Tuning (or fine tuning), we can create different tuning offsets on a per-voice basis (depending on LFO de-syncronization). The downside of this LFO method is that it generates "a more artificial motion". Natural wave motion occurs when you combine two or more oscillators that are not perfectly in tune.
The tuning offsets will naturally generate motion through additive and subtractive interference of the different wavelengths/frequencies. LFOs generate motion above and beyond the natural wave interference motion, because they change the tuning of each oscillator over time. Note: It may sound good to have a little of this artificial motion (ie: frequency randomness / frequency drift per oscillator), but the underlying foundation for a given oscillator should be a semi-stable centerpoint of its given tuning offset.
LFOs result in constant changing of the tuning of each oscillator they are routed to, and at medium to high values, this pronounced motion is non-realistic when comparing to old VCO synths, or with analog instruments. It is less noticeable for stabs, leads or patches with quick decay, but if you're playing strings, pads or patches with long decay, this extra motion sounds more artificial.
Again, take a guitar, or violin, or any number of other analog/acoustic instruments, and you'll find tuning offsets per voice and string, but not much tuning motion. (Note: performance variation and vibrato is another topic)
LFO Random at a Low Rate
There is another method of using a Random LFO with Key Sync on and very low rate, to generate new random numbers offsetting oscillator frequencies per key strike. There are several downsides to this method as well. First, since the LFOs are generating random values, you are playing Russian roulette with your detuning character.
You may play a few chords and they sound great together, because the random values for each voice and oscillator have matched up well, but then you may play another chord, and get a bunch of weird dissonant sound. This is due to LFOs generating random values in divergent phases (+/-) for given oscillators within a voice, and in comparison with other voices. Random pronounced dissonance can be avoided if you specifically model voices and their given LFOs with static offsets, since you have control over the divergence of detuning between oscillators in a given voice. At the top of this page is a video that compares random LFO to VCM methodologies and shows this effect. (
VCM vs LFO Random Comparison)
In addition to the random dissonance with this method, you have less repeatable behavior for a given sound design from session to session. You may play during a song recording and get everything to line up beautifully with organic detuning offsets, but then you might bring the same synth and patch to a venue to play live and it may sound significantly different, due to randomness altering the notes everytime you play them. With VCM voice modeling, you get much better repeatable performance from session to session, with the same patch.
Further, with a voice modeling implementation like described with the Prophet Rev2, you can achieve defined virtual voice counts, and replicate the defined patterns of imperfection for a set amount of voices or players in a round robin type of voice allocation scheme (this is not possible using random LFOs).
And finally, the VCM method doesn't use up multiple LFOs, which tend to have a premium value in terms of sound design. If using a synth with only 2-3 LFOs, you're most likely going to want those available for pitch modulation, vibrato, shape mod like PWM, and other effects and tone shaping.
Two Voices, Two Osc Each, Natural Detune vs Osc Slop
Above: Each window above shows a voice with two oscillators.
On top, Natural Wave Interference Motion is created by a fine tune offset between two oscillators.
The bottom window shows the effects of Osc Slop / Multiple LFOs - note the constant acceleration and deceleration / rate changes, high speed detuned motion as LFOs move apart, direction changes as one or both LFOs reach apex, and sometimes long sections of motion freeze when LFO motion and offsets align.
Osc Slop (or LFOs) can add some realistic variance at small amounts, but beyond that, you may get a bunch of exaggerated drifting motion, noticable acceleration changes and erratic behavior when combining multiple voices.
Oscillator Slop / Complex Random Voice Detuning
Many modern poly-synths include complex macro-type algorithms that are dedicated to giving synth voices imperfections.
These algorithms generate a lot of drifting motion and randomness once you start getting up into medium or larger amounts. Osc Slop produces a complex motion on each oscillator of each voice - this motion falls into the category of "artificial wave motion" as mentioned above - with constant rate and accelleration changes, high speed movement, freezes, and direction changes due to synchronous and asynchronous LFO movement between oscillators.
If you are modeling a wind or string patch, and using some Osc Slop (or LFOs) to give voices a unique character, the constant detuning motion will be unrealistic. Imagine an ensemble of four violinists, but as they play, there is an extra person constantly twisting the tuners of each string on their instruments. Or a brass ensemble where all the instruments are changing tuning as player's perform. This modeling method allows each voice to have its own unique character, but with some stability in the tuning offsets.
Even without a constant drifting motion, generating voice offsets / oscillator offsets randomly is not going to be as accurate as using a voice lookup table, with repeating patterns depending on performance and phrasing of chords. Also, this voice modeling methodology is meant to not only address oscillator tuning, but also other aspects of voice-osc relationship (shape mod, noise, osc levels, etc) as well other behaviors associated with VCFs, VCAs and envelopes.
Note: To be clear - Oscillator Slop and LFO Drift can still be valuable tools to use in sound design, producing a different, more artificial phasing motion. The first rule of sound design is: If it sounds good and right for your needs, go ahead and use it.
I've just found that in most patches that I used Osc Slop before, I'm now replacing that with the stable offsets of voice modeling to get the more natural phasing sound that works well for emulating classic VCO poly synths and acoustic ensembles.
Voice Frequency Spread
Some modern poly synths have a function that performs either a random or uniform spread of poly voice detuning. If it's random, you will not get the repeated patterns of voices with certain character. If its uniform, you may get patterns, though they will be at whatever your poly voice allocation is. Also, you don't get to fine tune the amounts individually. One common scenario in older VCO synths is having several voices that are well tamed, but just one or two voices that have more pronounced tuning issues. By using lookup table type of modulation, you can model this.
With a uniform or random spread, you lose that control. In addition, depending on implementation of spread, it may only affect the voice as a whole (all oscillators), instead of having control down to the individual component level oscillators with unique detuning for each. This type of spread modeling is good, but it's still more of an approximation, where we can have more definition to the character. Also, the lookup table paradigm allows for adjusting per voice / per oscillator performance characteristics not only on fine tune frequency, but a variety of other behaviors in the VCO, VCF and VCA sections.
To Sum Up The Existing Approaches
Drifing motion and randomness are valuable tools that can add some realism, especially for older VCO synth emulation, but we are better served with defining the underlying order of voices and offsets of component values first, and then using a small amount of additional detuning drift or randomness on top of that foundation of modeled order. This approach leads to better emulation of old VCO synths, and real world analog instruments and ensembles.
Part 3: Voice Modeling Implementation
Setting Modulation Offsets with Voice Component Modeling
This approach requires access to a "Lookup Table" that defines component offsets for each voice independently - like in the Memory Moog mockup table above.
For future generations of poly synths, this type of component based lookup table could be implemented as a core function of the synthesizer, in order to more accurately be able to model old classic VCO synths, as well as other poly voice analog and acoustic instruments.
 A Case Study - The DSI Prophet Rev 2 Synthesizer
A Case Study - The DSI Prophet Rev 2 Synthesizer
I have done extensive testing with my Prophet Rev2, and now converted dozens of my custom patches over to this type of VCM approach. To my ears, they sound great... I'm excited to hear what others think.
There is a level of realism to analog / acoustic instruments that I could not achieve before. When building patches to emulate old VCO synths, they sound more like Old VCO Synth Patches, rather than patches using randomness and pronounced drifting motion to approximate that character.
You can build out synth templates with defined voice counts and offsets for each voice component, better modeling the character of synths like the Memory Moog, CS80, Prophet 5, Jupiter-8, OBXA, and others.
Note: If you would like some free patch templates to build your own VCM patches from, Email Me, and I'll send a pack of Rev2 patch templates for 4-Voice, 5-Voice, 6-Voice and 8-Voice VCM setups for Old VCO Synth Modeling (with all the stuff wired up). Or follow along below:
Let the Jury-Rigging Begin
To be clear from the start, there are limitations and shortcomings with implementing voice component modeling with existing products on the market. They were not designed for this so we'll be doing a bit of jury-rigging and creative modulation routing to pull this off.
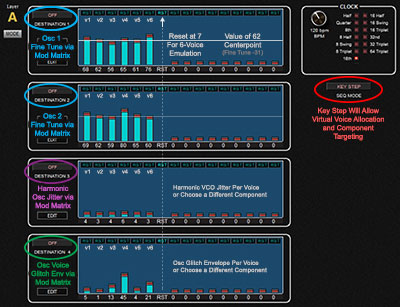 Gated Sequencer Setup
Gated Sequencer Setup
We're using the Gated Sequencer as a Voice-Component Lookup Table, with assignable, virtual poly voice count, and individual values for up to four component parameters per voice.
The first part of this setup is to switch the Gated Sequencer into "Key Step" mode, and then set a reset (RST) in each lane that corresponds to the number of "virtual voices" you want your patch based on.
If you're trying to model a Prophet 5, set the reset at step six for all lanes. If you want to model a Memory Moog, set reset at step seven for all lanes, etc... You're virtually defining how voices will create repeated patterns of imperfection, like on the actual synths of yester-year.
For other analog and acoustic instruments, you can play around with specific voice allocations and see what type of variation and repeating patterns suit the sound your going for when playing polyphonic passages.
Next, you get to choose which four characteristics / components you want to model on a voice-by-voice level.
The top two are probably going to be Osc1 and Osc2 Tuning (Fine Tuning via Mod Matrix Scaling Method described below). Now you've got two more component slots.
In this example, I'm using the third lane to adjust Harmonic Jitter / High Frequency Jitter per voice, and the fourth lane controls the amplitude of an Envelope 3 Delayed Glitch Amount that I've modeled.
These are two types of imperfections you may run into with older VCO synths.
You could choose completely different components / characteristics to model though, and they will be specific to the voice being triggered. I've experimented with several other voice-component specific offsets. If you want to "virtually age" your VCF Filter chips, try routing one lane to VCF cutoff amount, and varying the offsets... now you've got filter fine tuning behavior that is modeled on a "per virtual voice card" basis. So each voice will have a unique filter character. There are dozens of other component based offsets that can be set in this way to virtually offset aspects of VCOs, VCFs, VCAs, envelope characteristics, etc...
Note: The way I have the Osc Fine Tuning setup in this example makes it so a value of 62 in the gated sequencer makes the oscillator perfectly in tune. I chose that as a centerpoint, so adjustments can be made sharp or flat in both directions. (to compensate for this starting point offset, I have set each of the Osc fine tuning controls to -31 value)
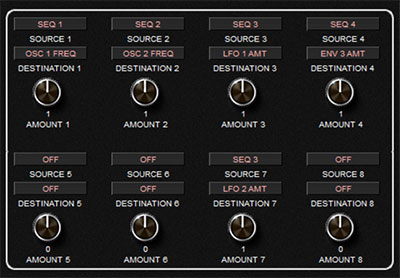 Using Mod Matrix to Scale Values for Finer Control
Using Mod Matrix to Scale Values for Finer Control
Unfortunately, there is no way to directly address Oscillator Fine Tuning as a modulation destination in the Prophet Rev2.
I'm hoping this will be a standard option in future boards.
There is a workaround however, by using Mod Matrix slots to scale values
In this example, we're routing the Osc1 and Osc2 frequency via the mod matrix, with a value of '1' as the amount for both.
This is not the actual value that gets passed on to the Osc Frequency though. It's taking the value from the Gated Sequencer and dividing that by the Gated Sequencer Maximum value, to get a fraction that is passed on.
For instance, when we have a value of 73 set in the gated sequencer voice-component lookup, when it is applied though the mod matrix, we're sending along 73/125 * 1 = 0.584 (125 is the max value in gated sequencer and the 1 is the amount we're multiplying by in the mod matrix) This workaround allows us to be able to precisely fine tune each oscillator, rather than doing it in 50 cent minimum increments (50 cents is the normal amount of offset you'd get by routing a value of 1 to Osc Freq)
LFO Setup, VCO Harmonic Jitter
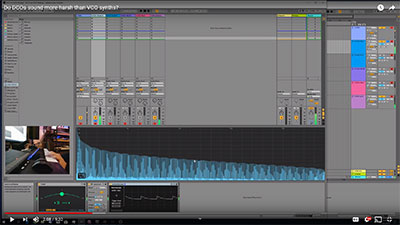
In this example, I'm using the third lane to model a high frequency Oscillator Tuning Jitter. This is a modulation method I've been experimenting with, in order to replicate the same sort of raw VCO oscillator frequency movement in higher harmonics. You can see more about experiments with VCO harmonic jitter here:
YouTube Video on VCO Harmonic Jitter.
In this example, I have the Seq 3 lane routed to both the Osc 1 Freq and Osc 2 Freq via two separate LFOs.
I'm using both mod matrix value scaling (like described above), plus then passing that on to the LFOs, which provide their own sort of scaling. LFO values are equivalent to just 1/4 that of a mod matrix value sent to the same destination.
This is how I was able to get ultra low range frequency jitter like I measured on raw VCOs (ie: less than 1 cent total range, with relatively high frequency).
Now Sprinkle Some Random Motion on Top
At this point, we have unique, per-voice tuning offsets modeled, along with some other parameters.
Now is a good time to sprinkle a little bit of randomness like Osc Slop on top.
As mentioned earlier, I've found that in patches where I had previously set Osc Slop to 5-15 value, now I use the voice-component modeling to define most of the per voice character, and then just add a touch of Osc Slop (1-3 value) -- just to give a tiny bit of randomness and unpredictable drift. Note: even at lowest settings, Osc Slop can add a good amount of drifting motion and detuning offset, when LFOs are in divergent phase.
Part 4: Overview, Benefits of Voice Component Modeling
There are several improvements in realism for modeling old VCO synths, as well as other analog and acoustic instruments:
I. Virtual Voice Count Definition, Patterns of Imperfection
Patterns of imperfections occur depending on number of voices defined and actual performance phrasing. If you're playing a series of three-note chords with a five voice synth (ie: Prophet 5), then each time you play the chords, the voice selection will cycle, and you'll get a slightly different character. For example: (1,2,3) (4,5,1) (2,3,4) (5,1,2) (3,4,5) (1,2,3) As you play, there will be repeating patterns to this behavior. This is one aspect of the character of Old VCO Poly Synths that would be more realistic.
You can turn your 16-voice poly synth into a virtual 4, 5, 6, or 8-voice synth... In this current implementation, this lookup table voice allocation occurs without the same voice stealing issues of older synths, but in future generations of this, even voice stealing could be modeled if you desired it for realism.
II. A Balance of Defined Order and Randomness
This method of "designed imperfection" relies on an underlying definition of order (ie: tuning offsets and other component level offsets), upon which some randomness and further modulation may be applied. Instead of relying on uniform or random detuning algorithms, you can fine tune your synth's character to have most voices close to perfect tuning, but you may choose to have one or two voices detuned a bit more. Early Analog Poly Synths were notorious for having tuning issues that were more pronounced on certain voices than others. If you research Memory Moog Tuning issues you'll see this topic appear often. This is another aspect of realism that this method achieves, and with a lookup table, specific voices and components can be fine tuned to the user's taste.
III. Reduced Dependence on Artificial Drifting Motion
Existing approaches are too focused on adding pronounced motion and drift to oscillators. This VCM method favors the type of "natural interference motion" generated by combining more stably tuned waves with offsets. After that foundation of "natural detuned motion" is built, then you can sprinkle a bit of the drifting motion / more artificial motion on top. It improves realism not only for old VCO Poly Synth modeling, but also for modeling other acoustic and analog instruments (stringed instruments, wind ensembles, etc)
IV. Modeling of Various Other Components on a Voice Basis (VCF, VCA, Envelopes, etc)
Per Voice Component Offsets
Routing ideas to model Old VCO Synths and Acoustic Instruments |
| Voice Component |
Routing (Mod Matrix Scaling) |
|
| Osc 1/2 Fine Tuning |
Mod Matrix > Osc Tuning |
| Osc 1/2 Tune Intonation |
Mod Matrix > Note Num > Osc Freq |
| Osc 1/2 Shape Variance |
Direct | Mod Matrix > Osc Shape |
| Osc 1/2 Glitch Env |
Mod Matrix > Env3 Amt > Osc Freq |
| Osc 1/2 Harmonic Jitter |
Mod Matrix > LFO > Osc Freq |
| Osc 1/2 Defined Drift |
Direct | Mod Matrix > LFO > Osc Freq |
| Osc General Detune Slop |
Direct | Mod Matrix > Osc Slop |
| Osc Levels |
Direct to Osc Mix |
| Voice Noise |
Direct to Noise Level |
| Sub Osc Amplitude |
Direct to Osc Sub Level |
| VCF Cutoff Offset |
Direct to Filter Cutoff |
| VCF Envelope Offset |
Direct to Filter Env Amt |
| Etc... |
Dozens of potential routings |
In addition to character modeling of oscillator tunings per voice, this lookup table method can apply to any number of additional parameters that may have equivalents in old VCO synths or real world analog instruments. For instance, we may model an offset in filter cutoff frequency on a per voice basis. VCFs are discreet electrical components that have tuning variance as well. We may want to model small differences to envelope behaviors, such as Attack or Decay speed. This approach allows us to model specific characteristics of various aspects of the synth.
V. Synth Character and Analog Poly Voice Snapshots
This method allows you to take a snapshot of a given older VCO poly synth, or analog/acoustic multi voice instrument or ensemble. You can model and save offsets to any number of component parameters, for a given day or venue. You may want to save multiple variations of a patch template for a MemoryMoog: one in ideal studio settings with perfectly dialed character, another emulating the wild untamed characteristics at hot and humid summer concert venue. Same goes for patches of multi-voice wind or string instruments - you can dial in specific tuning offsets per voice, and other component level variances that may define character at a given point in time.
VI. More Consistent Performance from Session to Session
As mentioned above, this method allows you to dial in per-voice character and save it into a patch as a sort of snapshot of a multi-voice instrument. Each time you bring up the patch, it will give you more consistent performance than patches using Osc Slop to give voice definition. Osc Slop uses a complex macro of free-running LFOs, so you will never get the same voice-by-voice character from one session to another... this can be particularly noticible at medium to higher values.
Is this a Magic Bullet for achieving Old VCO Synth Emulation?
No - and the main reason is due to filter implementations. There are several types of VCF filter circuits that have been used by a variety of classic synthesizers (Moog Ladder, SEM State Variable, Steiner Parker Multimode, Prophet Curtis Filter, etc) Each of these VCF filters shape and color the raw oscillator sound in unique ways. There are also other small differences in VCAs and general circuit design that will give different boards certain characteristics.
But, I do believe this VCM method greatly improves Old VCO Synth Emulation, and given the same type of VCF filters, you may be able to get 95% of the way there to a MemoryMoog, Prophet5, CS80 or Jupiter character, where you could only get maybe 90% before.
If synth manufacturers make some improvements in next generation of releases, I think the gap will only close further, as we will be able to assign and address specifics of poly voice usage, and do detailed modeling of electrical characteristics down to the virtual component chip level... all via an expanded lookup table matrix.
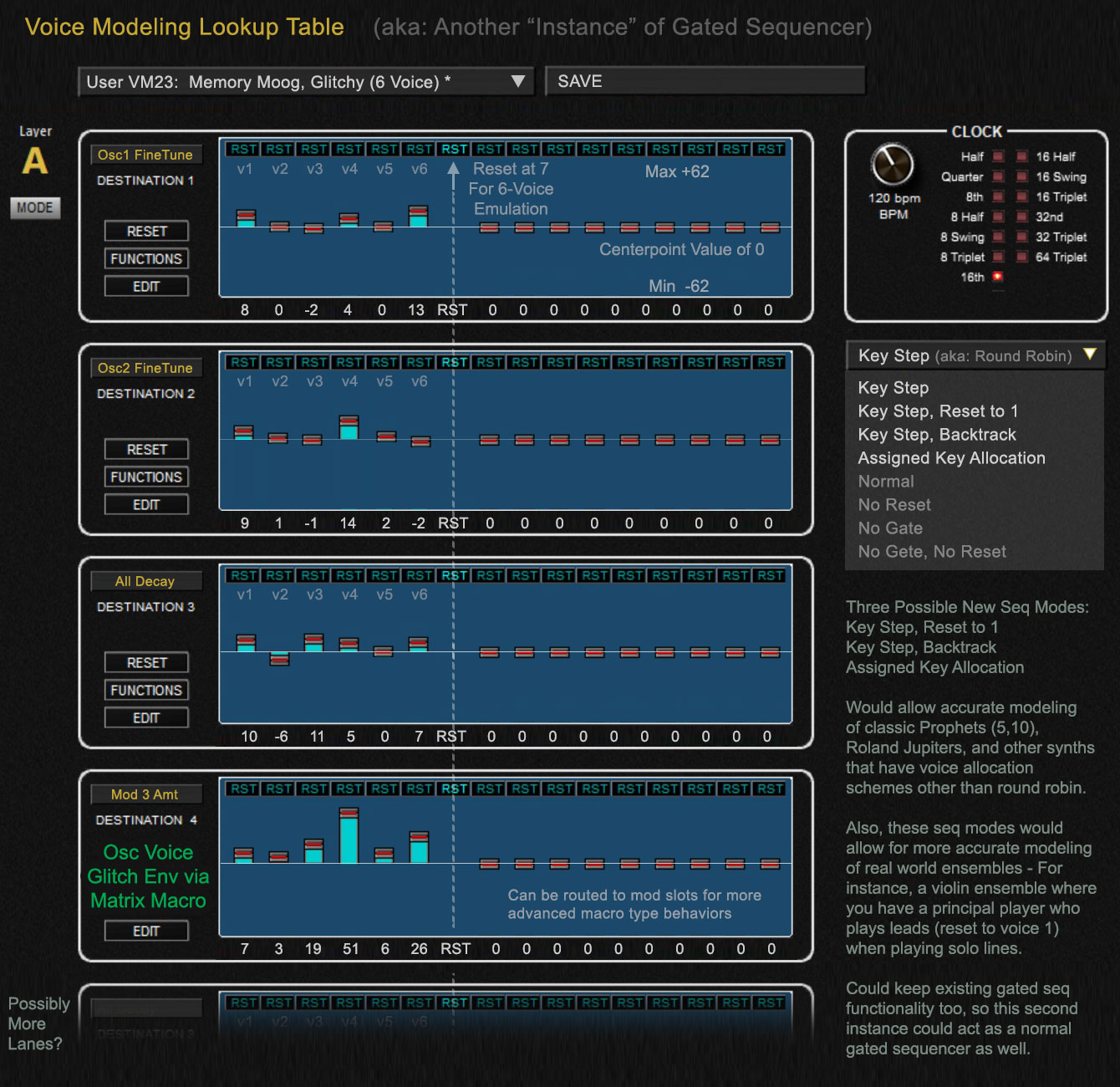
Part 5: Next Generation, Future Implementations, Thoughts
These development thoughts are tailored to the Prophet Rev2 and a hypothetical Rev3 type of synth in the future. The Rev2 is an versatile and great sounding synth. It already can perform a basic implementation of this type of modeling. However, there are many limitations and shortcomings currently. Below I will discuss how improvements could be made to future boards. These same type of adjustments and advances will apply to any synth using this type of lookup table modeling of components on a voice basis.
Basic Advancements
The current implementation of the Gated Sequencer on the Rev2 works quite well to achieve this type of modeling, however, expanding the size of the gated sequencer would be very beneficial, as we're currently limited to modeling four characteristics at the voice-level.
By just increasing gated sequencer lanes to eight instead of four would be a basic next step and significant move forward.
Optimal Lookup Table Setup
Optimally, a Component-Voice Lookup Table could be built as another separate table from the Gated Sequencer. So you would have note sequencer, gated sequencer, and component lookup table as three separate modules.
If memory and processing power is not a major constraint, it would be great to have 12 or more lanes of data that could be modeled. Each lane can correspond to a modulation offset of a single parameter, per voice, and may include further control over Oscillator section, as well as fine tuning characteristics of VCFs, VCAs, envelopes and LFO performance on a voice-by-voice basis.
Alternatively, if the current model of the Four Lane Gated Sequencer could just be copied one or two times, that would be an interesting implementation. If we had access to three separate, 4-lane gated sequencers, we could define two for voice-component lookup modeling, and still have a third to use for more traditional animated type of behavior sync to bpm/clock. (this is assuming that each gated sequencer could be individually defined as Gated, No Gate, No Reset, Key Step, etc)
Additional Triggering Modes Tied to Note-Off and All-Off Logic
The Key Step mode works well for this type of implementation, however, adding a couple additional modes would increase flexibility and realism when modeling certain older synths.
Key Step, Reset - This mode would work like Key Step mode, however, once all voices are off for a moment, the key step index would return to the #1 position. This type of voice allocation reset behavior is present in some synths, and also might replicate effects of an ensemble of violins or trumpets or other instruments, where there is a first trumpet who plays monophonic leads (and has same character), but when other voices accompany, then you get more variation in character.
Key Step, Backtrack - This mode would work like key step reset, but if you hold down a bass note and chord, then keep the bass note held and change upper notes, those key step notes would always take the value in the lowest available key-step slot. ie: if you play a root bass note, with a three note chord over top, the first four key steps will be triggered. Then you release the top chord while still holding down the bass note, and play a different three note chord on top, those notes would take the values from key step 2,3,4 (backtracking to lowest unused keystep value) rather than moving on to higher key step positions. This behavior would allow modeling of other types of voice allocations in classic synths. The Roland Jupiter-8 is one example, where default voice allocation always backtracks to lowest available voice.
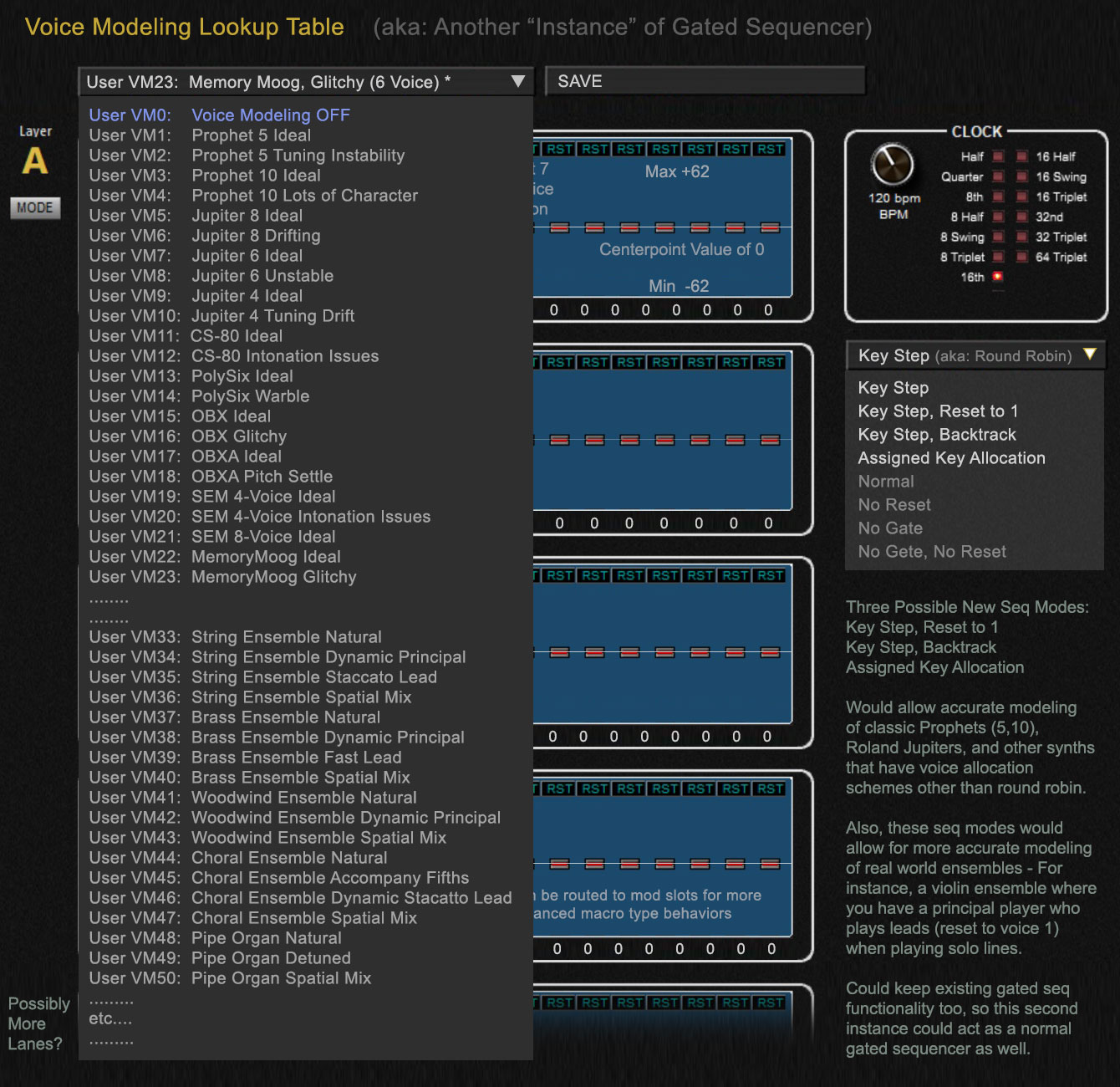 Saving Voice Modeled Snapshots
Saving Voice Modeled Snapshots
It would be useful to have several "virtual snapshots" of old synthesizers and acoustic/analog ensembles modeled, which could be loaded into a given patch. This type of saving/loading of gated sequencer setup can actually be done with the SoundTower editor currently (using Gated Sequencer Templates functionality)... so maybe that is sufficient, but the same sort of Lookup Table Template loading/saving might be a valuable option to have for users programming patches without an editor.
As an example, you might have several templates with names like "6v Memory Moog Ideal", "6v Memory Moog Hot and Humid", "6v Memory Moog Voice Five Failing", "5v Prophet 5 Ideal Character", "5v Prophet 5 Needing Service", "8v CS-80 Ideal", "4v Trumpet Ensemble", "8v Wind Ensemble", etc... where each lookup table has unique variation to offsets in each voice.
Improvements to Modulation Matrix, Transforms, Destinations
In general, it would be great for next generation of DSI synths to have a variety of Modulation Transforms available for each Mod Matrix slot (that can mathematically scale or skew values as needed). Also, making Osc Fine Tune into a destination would be helpful, though the mod transforms may be adequate for this lack of fine tune destination, as well as allowing all kinds of other advanced modulations. Mod*2, Mod*4, Mod*8, Mod/2, Mod/4, Mod/8, Mod Squared, Mod Cubed, Mod Root, Mod Cube Root, Mod Thresholds, etc...